
Category — doing the math
DC intersections with Mathematica
Without the quadrant designation, several intersections in Washington–“6th and C,” for example–are ambiguous. “6th and C” can refer to a place in NW, NE, SW, or SE DC. Because of this duplication of streets and intersections, the quadrant is usually–but not always–specified. I’ve been curious for some time to know exactly how many doubly-, triply-, and quadruply-redundant intersections there are in DC, and it’s another fun example combining Mathematica 7‘s .shp file import with the GIS data that the DC government makes available.
How many are there? I calculate:
| Quadrants: | 2 | 3 | 4 |
| Intersections: | 418 | 71 | 28 |
The 28 intersections that appear in all 4 quadrants are:
14th & D, 9th & G, 7th & I, 7th & E, 7th & G, 7th & D, 6th & C, 6th & G, 6th & D, 6th & I, 6th & E, 4th & M, 4th & G, 4th & E, 4th & D, 4th & I, 3rd & M, 3rd & C, 3rd & K, 3rd & D, 3rd & G, 3rd & E, 3rd & I, 2nd & E, 2nd & C, 1st & M, 1st & C, 1st & N
Plotted on a map:

Color coded map of intersections in DC.
Update: Here’s a larger PDF version.
Here’s how I made the map and did the calculations:
March 1, 2009 4 Comments
Red Street, Blue Street
In the end, I went with the upgrade to Mathematica 7. Of all the new features, the one that really hooked me–which is comparatively minor, compared to all the other new features–is the ability to import SHP files. The importation is not terribly well documented nor is there much additional support, but it was pretty easy to do a few nifty things with the DC Street Centerline file.
As you may know, there is a street in DC for every state in the union. Pennsylvania Avenue is probably the most famous of these; the White House sits at 1600 Pennsylvania Ave NW. I used to live on Massachusetts Avenue. So my first idea was to make a street map of DC in which the state-named streets were colored red-ish or blue-ish depending on their vote in the recent election.
Here it is:

Read on to see how I made it:
January 17, 2009 1 Comment
The next Mathematica
To me, an intermediate and somewhat casual Mathematica user, the news that Mathematica 7 had been released was a surprise. Surprising to me because Mathematica usually goes much longer between major-digit releases; I would have anticipated this to be Version 6.1. For fun, I’ve plotted the history of Mathematica versions1 :

Release dates of versions of Mathematica
Mathematica 6 was a substantial upgrade: the graphics system was completely overhauled, the curated data, that I’ve used as the basis for some posts here, was added, and the ability for dynamic interactivity was added with Manipulate and Dynamic.
I am not, of course, a major Mathematica user. In fact, although I’m a physicist, I haven’t made tremendously much use of Mathematica for my professional work. This is partly because I tend to deal with relatively small data sets, for which a GUI-based data analysis tool is usually easier to work with than the command-line Mathematica. And I’d consider myself an advanced user of Pro Fit, the data analysis tool that’s made all the graphs for all the work I’ve done since about 1998.
In fact, my Mathematica license is my own personal one. As a graduate student, I bought the Student version of Mathematica, which they allow you to upgrade to a full professional license for only a few hundred dollars, compared to the $2500 list price of a new professional license.
Wolfram really wants its users to buy Premier Service, a several hundred dollars per year service which entitles you to all upgrades, major and minor. If you don’t buy premier service, then you need to pay for all upgrades, even the N.M.X to N.M.X+1 minor bug-fixing upgrades. And without premier service, you’re not even supposed to install Mathematica on more than one computer. Draconian and greedy, if you ask me, but they can do that, because they’re Wolfram. And for tech-heavy firms that make heavy use of Mathematica and get millions of dollars worth of value from whatever they compute in Mathematica, it makes sense. But it makes it very difficult to be a casual user.
And even though your existing copy can do everything it could the day you bought it, once the difference between your copy and the current release gets large enough, there is no longer an upgrade path. I think this is one of the motivations to release this as version 7 and not 6.1: I don’t recall the precise figure, but Wolfram generally offers an upgrade path only for jumps smaller than 1.5. If this is still the case,2 what this does is cut off anyone who hadn’t upgraded to version 6. Update: enough with the conspiracy theories! Wolfram clears up the upgrade policy in the comments.
In my case, with Version 6.0.1, I have a choice of paying $750, and getting a year of Premier Service, or paying $500 for just version 7.0.0 with no service. Out of my own pocket, ouch! But what makes it really enticing, for me, is that Mathematica now reads SHP files. These are the Geographic Information System data files, promulgated by ESRI, in which vector-valued geographic data is commonly exchanged. In particular, the DC Office of Planning makes an amazingly large collection of DC GIS data available in SHP format. The possibility for quantitative analysis of DC mapping data is very tantalizing.
Of course, Wolfram wouldn’t release a major number upgrade without hundreds of other new features. As of yet, there isn’t much substantial written about version 7. I did find some notes from a beta-tester and from a college math teacher. I’ll probably buy it, even though it would mean delaying other expensive toys that I want.
- most of the dates come from the Wolfram News Archive, some from the Mathematica scrapbook pages [↩]
- I’ve asked Wolfram, but haven’t received a reply. [↩]
November 22, 2008 3 Comments
Twenty megawatts in your hands
I needed to buy more gasoline for the car today, and I decided to see how long it took to fill the tank. I bought ten and a half gallons of gas, and it took 70 seconds to fill it up. Although filling up a gas tank is something that millions of Americans do every day, it’s really remarkable when you stop and think about the energy transfer going on.
Gasoline has, approximately, 113,000 BTUs per gallon.1 One BTU is 1055 Joules. So I transferred 1.25 Billion Joules in those 70 seconds, which is a rate of 17.9 megawatts. When you consider that you spend less than two minutes pumping the same amount of energy you burn in four hours of driving, it’s not surprising that you end up with such a high power. What’s more interesting, I think, is to contemplate the rather fundamental limits this puts on plug-in electric cars.
Internal combustion engines, according to Wikipedia, are only about 20% efficient, which is to say, for every 100 BTUs of thermal energy consumed by the engine, you get 20 BTUs of mechanical energy out. This is, in large part, a consequence of fundamental thermodynamics. Although electric motors can be pretty close to perfectly efficient, a similar thermal-to-electric efficiency hit would be taken at the power plant.
Let’s consider, then, that we want a similar car to mine, but electric. Instead of 1.25 gigajoules, we need to have 250 megajoules. Battery charging can be pretty efficient, at 90% or so, which means we’d supply 280 megajoules. If we expect the filling-up time to be comparable to that of gasoline cars–call it 100 seconds for simplicity–then we’d need to supply 2.8 megawatts of power. At 240 Volts, which is the voltage we get in our homes, this would require 11700 amps; if you used 1000 Volts, it would take 2800 amps. Although equipment exists2 to handle these voltage and current levels, it is an understatement to say that it cannot be handled as casually as gasoline pumps are handled. Nor is it clear that any battery system would actually be able to accept this much power.
A linear relationship exists between the power requirement for filling, and the vehicle range, the vehicle power, and the time for a filling. If you’re satisfied with half the range of a regular vehicle, for example, you could use half the filling power. Let’s imagine that you’d be happy for the filling to take ten times as long as with gasoline, or 1000 seconds, just under 17 minutes. At this level, you’d need 280 kilowatts of power. If battery charging is 90% efficient, that means 10% of the power is going to be dissipated as heat, which in this case would be 28 kilowatts.
For comparison, a typical energy consumption rate for a home furnace is 100,000 BTU per hour, about 28 BTU per second, or 29.3 kilowatts. Which means that the waste heat dissipated during charging for the example–of a 1000 second fill for a vehicle with similar range and power as a modest gasoline powered sedan, at 90% charging efficiency–is as much as the entire output of a home furnace.
No wonder overnight charges are the standard.
- Summer and winter blends have slightly more and less, respectively. [↩]
- think about how large the wires would need to be [↩]
November 13, 2008 4 Comments
Dow Jones and Mathematica
A recent post by economist-blogger Brad DeLong, which was also picked up Matthew Yglesias, mused upon the clustering of the Dow Jones Industrial Average clustered near values starting with 1. He showed a chart with the years 1971–1984, and 1996–2008 circled, when the Dow appeared to fluctuate near 1000 and 10000, respectively. Many commenters quickly jumped to point out that this was an example of Benford’s Law, which says, essentially, that if you’re throwing darts at a logarithmically shaped dartboard, you’re going to hit “1” more often than any other digit. If you pick random values of some phenomenon that is logarithmically distributed, you should get values beginning with “1” about 30% of the time, which makes sense if you’ve ever looked at log scale graph paper.
It occurred to me that this is an easy thing to investigate with Mathematica, much like my earlier post on the Bailout. Mathematica 6 includes access to a huge library of curated data, including historical values of the Dow Jones Industrial average and other indices (and individual stocks, and so forth). The function here is FinancialData, which Wolfram cautions is experimental: I believe they get the data from the same source as, say, Yahoo! Finance, and just do the conversions to make it automatically importable into Mathematica. That is, it is no more reliable than other web-based archives. The computations are absurdly easy, taking only a few lines of Mathematica code.
The graph I (eventually) produced shows the relative frequencies of first digits that are calculated by Benford’s Law, together with the relative frequencies of the leading digits from the Dow Jones Industrial Average, the S&P 500, the NASDAQ Composite index, the DAX 30, and the Nikkei 225:

November 1, 2008 No Comments
Bailout and Mathematica
A friend of mine (and regular commenter here) has pointed out that, even if the $700,000,000,000 bailout passes, and adds to our National Debt, we’d still have a Debt-to-GDP ratio that was less than Germany’s.1 Wikipedia says that the US National Debt is 60.8% of our GDP, that Germany’s is 63.1%, and that our GDP is $13.8 trillion. Well, add $700 billion to 60.8% of $13.8 trillion and the new figure is 65.8%–pretty close; there are different ways of measuring both GDP and the Debt.
But I realized that this sort of comparison is something that Mathematica 6 is supposed to be good at. Mathematica is an amazingly powerful system for doing mathematics on a computer. Its strength, traditionally, has been symbolic manipulation–I most often use it for the Integrate command, which can do most of the integrals that in grad school I’d look up in Gradshteyn and Ryzhik. Version 6 has added, amongst other things, a huge library of curated data, loaded over the Internet, that’s relatively straightforward to use.
The command CountryData gives access to all sorts of country-by-country information, including “GDP” and “GovernmentDebt”. So following one of the examples in the documentation, I produced this graph, plotting the Debt-to-GDP ratio versus GDP for (nearly) all the countries for which Mathematica has data. (Note that the x-axis is a logarithmic scale.) The United States, before and after a $700 billion bailout, are shown in green and red, respectively.
If the xhtml export actually works the way it’s supposed to, you should be able to hover your mouse cursor over each point and have a little ToolTip pop up telling you which country the data are for.
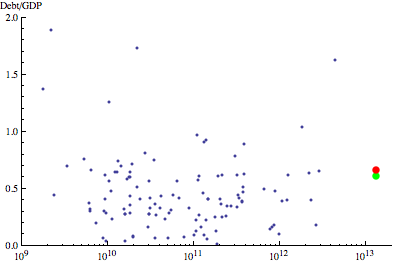
|
| GDP [$US] |
Mathematica has a syntax that strikes many as arcane. Since I learned about computers with procedural programming, and haven’t really done any functional programming, I too struggle to get Mathematica to do what I want it to do. But one can often do complicated things, such as the above graph, with a very compact command. To make the main graph–the red and green dots are relatively trivial additions–the command I used is:
[Read more →]
- He is, nevertheless, against the bailout. [↩]
October 1, 2008 1 Comment
Iced tea
I like to make iced tea during the summer months. Not that vile powdered stuff, but real tea or herbal infusions. To make it quickly–so one doesn’t have to wait for near-boiling tea to cool all the way down to an icy-cold temperature, I prefer to brew double-strength tea and pour it over ice, such that most of the ice melts, and the near-boiling tea cools, together making an appropriately strong chilled drink.
How much ice does one need? Well, to cool 1 gram of boiling water down to the freezing point, 100 calories1 have to be extracted from it. Melting 1 gram of ice takes about 80 calories of heat. So a mixture of 56% (by weight) ice and 44% boiling tea will melt all the ice and leave the final mixture at 32°F.
How do you measure this amount of ice? Well, you could weigh it, but that’s not always convenient. Here’s a bit of mathematics to justify a simple approximation: The density of ice is approximately 92% that of liquid water. If you fill a container with ice cubes–or with any solid particles, for that matter–there is a fair amount of air space between the grains. If ice cubes were spherical, then only about 64% of the volume would be ice, and the rest air–this is known as the random close-packed fraction. Ice cubes aren’t spheres, but the fraction should be roughly the same. Which means that if you fill a container up with ice cubes, they would melt to a volume about 59% of that of the container. If you add 50% of the volume of the container of boiling water, the ice would represent about 54% of the total mass of water and ice, and mixing the two together you’d end up with a volume of liquid equal to 109% the volume of the container, at 32°F. To avoid overflow, you’d need to use slightly less ice and boiling water.
So, my iced-tea algorithm:
- Fill a container most of the way up with ice cubes
- Measure out as much tea as you need for the full volume of the container
- Brew the tea using a volume of water that’s slightly less than half that of the volume of the container
- Pour the brewed double-strength tea (through a strainer, if necessary) into the ice-filled container
- Stir to cool the tea and melt the ice; most of the ice will melt. Since the brewed tea will have cooled off a bit while steeping, it won’t have enough heat to melt all the ice and so there will still be some ice left.
The tea leaves will absorb some of the water, and many containers hold (slightly) more than their nominal volume, so using (say) exactly 1 quart of water to make tea in a 2-quart container shouldn’t present any problems.
To brew, I’ve adopted the Cook’s Illustrated technique of mixing the tea and cold water in a saucepan, heating over medium heat to 190°F, then shutting off the heat to let steep for 3 or so more minutes: all total, the brewing should take about 15 minutes.
I’m fond of a mint infusion: for a 2 quart container, use 2 Tablespoons dried mint. I also like minted iced tea, for which I use a mixture of 4 teaspoons loose tea plus 3 teaspoons mint for a 2 quart container.
- Thermodynamic calories, not food Calories. A food Calories, spelled with a capital C, is 1000 thermodynamic calories. [↩]
July 2, 2008 2 Comments
Paul Sally.
The recent issue of the alumni magazine from my undergraduate alma mater, The University of Chicago, includes a profile of mathematician Paul Sally, who taught the Honors Analysis in Rn sequence I took in my second year.
Despite the rigorously intellectual image of itself that the University promotes, the alumni magazine is usually as circumspect as an in-flight magazine. Of course the primary purpose of the magazine is to cultivate us as donors, so on-campus controversy, intellectual or otherwise, gets scant attention. The article on Sally certainly follows the magazine’s formula of uncritical boosterism, but I still found it a delight to read: it took me back to what was probably the most intellectually fulfilling experience of my academic career, a time when all the promotional slogans about the life of the mind were very real for me.
Although my enthusiasm for working in a lab led me to choose physics over mathematics, I still have a fondness for pure mathematics. I retain a handful of habits that are more a part of math culture than physics culture.1 Sally’s course kept me on the fence between the two disciplines.
Sally delivered his classes entirely without notes, and the course rarely made reference to the assigned book (a cheap Dover reprint and a small volume from Spivak). He led a “discussion session,” Tuesday evenings from 6:30 until 8 or 9, stretching the amount of class time. He told us he expected at least 25 hours per week from us, at one point advising us to make posters which read “Mathematics… is a full time job.” It was mathematics by immersion.
Not every teacher can pull this off so successfully: it’s easy enough to assign lots and lots of work, but the combination of a heavy workload and an uninspiring instructor usually results in lots of incomplete assignments.
Sally once remarked that, as you continue in mathematics, you get to a point where hard work is not only necessary, but also sufficient, to prove theorems and make progress. He was getting us to develop the sort of attitude and work ethic to reach that point.
There are many things I learned in college that I’ve now forgotten, many problems I can no longer solve. I don’t know how much review it would take for me to be able to solve the problems from Honors Analysis again, but, 15 years on, I feel I still have a well-developed understanding of the structure of the real numbers.
Here’s another article about Sally, for winning a teaching award.
- In particular, I can’t stand the common-in-physics habit of using the word “finite” when what is really meant is “non-zero” or “infinitesimal.” [↩]
May 29, 2008 No Comments
Scale in the media
I lamented in an earlier post that questions of scale are all too often left out of discussions of environmental solutions. To recent pieces that bring the issue up:
Michael Pollan’s Why Bother?, from last Sunday’s New York Times Magazine, opens by recounting what for Pollan was the “most upsetting moment” of An Inconvenient Truth: the “immense disproportion between the magnitude of the problem Gore had described and the puniness of what he was asking us to do about it.” Pollan defends notions of virtue and the steps, particularly gardening, that individuals might take to reduce their individual carbon footprints, vis-à-vis other responses to the climate crisis such as hopingfor some future technology. He writes: “Cheap energy, which gives us climate change, fosters precisely the mentality that makes dealing with climate change in our own lives seem impossibly difficult…. Al Gore asks us to change the light bulbs because he probably can’t imagine us doing anything much more challenging, like, say, growing some portion of our own food.”
Second, the April 12th Sierra Club Radio podcast has a segment with Bob Schildgen—Mr. Green—promoting his new book, which compiles questions and answers from his column in Sierra magazine. On the question of paper vs plastic (his answer–neither; bring your own bag), he encourages listeners to put things into perspective by mentioning that you likely burn as much petroleum in one trip to the grocery store as it takes to make all the plastic bags you’d use in a whole year. I can’t find his numbers online, but using the figures I wrote about earlier: 330 bags per American per year, 200 bags per gallon, so just over one and a half gallons of oil per American devoted to plastic bags. At 20 miles per gallon, you could make a round trip to a supermarket 15 miles away. Right order of magnitude, but I think you could travel a bit farther on that amount of gas.
This exercise in scale is then thrown out the window later in the interview, when host Orli Cotel asks the heavily loaded question: “For our listners who do own cars or need cars for whatever reason, what tips can you give us, as Mr. Green, to help reduce the amount of gas that we’re using, besides of course cutting back on car travel?” (As if there’s some secret, magic way to drive without using gas that only the hardcore enviros know about.) Mr. Green goes on to mention that Americans lose about 4 million gallons of gasoline per day because of underinflated tires. Of course, he doesn’t put this into perspective: that’s about 1% of our daily gasoline consumption; we burn through 4 million gallons of gasoline in about 15 minutes.
April 25, 2008 No Comments
March Madness wrap-up
Well, I didn’t place in the top two of the March Madness pool I entered this year, but both my brackets did manage to beat all my other family members’ brackets. As I wrote in my previous entry, I also filled out a third bracket, based entirely on a sophisticated ratings scheme. I entered this bracket in the ESPN and Washington Post tourney contests, but not the pool, as it was too boring to fill out. My loss!
Out of 5898 entries in the Washington Post pool, this third bracket placed 52nd; out of what I think were about 3 million ESPN brackets, it finished 33229th. If I had entered it in my brother’s pool, it would have scored 465 points and won.
Let’s have a look at round-by-round performance to answer some bracket questions.
| 1st | S16 | E8 | F4 | semi | champ | PTS | |
|---|---|---|---|---|---|---|---|
| My brackets | |||||||
| pundits | 24 | 9 | 6 | 3 | 1 | 0 | 385 |
| Statistics | 22 | 10 | 5 | 3 | 1 | 1 | 400 |
| PYTHAG | 24 | 12 | 6 | 4 | 1 | 1 | 465 |
| Contest winners | |||||||
| ESPN winner | 26 | 13 | 9 | 4 | 2 | 1 | 555 |
| WaPost winner | 26 | 8 | 7 | 4 | 2 | 1 | 475 |
| CBS pundits | |||||||
| Denis Dodd | 23 | 11 | 5 | 3 | 0 | 0 | 360 |
| Michael Freeman | 24 | 9 | 4 | 1 | 0 | 0 | 290 |
| Gary Parrish | 23 | 9 | 6 | 3 | 1 | 0 | 380 |
| Brian De Los Santos | 23 | 9 | 6 | 2 | 0 | 0 | 335 |
| Gregg Doyel | 22 | 11 | 5 | 3 | 0 | 0 | 355 |
| Washington Post pundit | |||||||
| Tony Kornheiser | 21 | 9 | 5 | 3 | 1 | 0 | 355 |
| CNN/SI pundits | |||||||
| Luke Winn | 24 | 11 | 6 | 2 | 0 | 0 | 360 |
| Grant Wahl | 23 | 10 | 7 | 2 | 1 | 0 | 385 |
| Stewart Mandel | 23 | 10 | 7 | 3 | 0 | 0 | 380 |
| Seth Davis | 20 | 9 | 6 | 2 | 1 | 0 | 345 |
| Kelli Anderson | 23 | 11 | 5 | 3 | 0 | 0 | 360 |
- How did the sports pundits do? Not very well.1 My brackets beat them.
- How did the individual pundits do compared to their consensus? Only CNN/SI’s Grant Wahl did as well as the consensus of pundits; the rest had lower scores. Sort of a reversal of the conventional wisdom on groupthink.
- How well do you have to do to win the ESPN or Washington Post contests? You need to nail the elite eight and on out. You need a good showing in the first two rounds, but you don’t have to be perfect. A handful of people in my brother’s pool got 26 first-round winners correct, the same number as the winners of the Post and ESPN contests. The Post winner only had 8 of the Sweet 16 correct, and if it had been an entry in my brother’s pool, it would have been mired somewhere in the middle. The ESPN winner picked 13 of the sweet 16–very good, of course, but at this point it still wouldn’t have been the leader in my brother’s pool.
It would be interesting to see how well the PYTHAG ratings would have predicted the tournament winners in previous years, although I doubt I’ll get around to it this year before my interest in bracket-prediction fades. But I think next year I’ll have to enter a bracket based on it, (and hope that nobody else does the same).
- At least for cheap-o non-ESPN Insider folks like me, the ESPN pundits’ complete brackets weren’t made available. They did better picking the final four than the CBS or CNN/SI pundits so perhaps they would have done better. [↩]
April 8, 2008 No Comments